Questionnaires for Everyone!

Streamlining cross-cultural questionnaire adaptation using LLM-generated translation quality feedback.
Team
- Myself: Ideation, literature review, task analysis, prototyping, usability testing (n=30), software development, online user testing, principal investigator for the project report
- Supervisor: Initial ideation, additional reporting, editing and commenting for the full project report, supervision, funding for user tests
Introduction
Questionnaire translation can be a tedious process for researchers. Not only is it resource-intensive, requiring the hiring of independent translators, it also can consume a lot of time going back and forth finding consensus, editing translations and running validation studies.
This effectively limits the ability of researchers from non-English-speaking regions from conducting questionnaire-based research work in their native languages. In turn, insights regarding phenomena in these regions are limited to educated populations that are proficient in English.
We had the idea to test if a large language model (namely, ChatGPT) could be used to lower costs at least during one part of the process. In this overview, I will explain the prototype ideation, development and testing process, tasks assigned to me.
Background
Before moving onto creating a prototype, I revieved existing questionnaire translation literature regarding commonly used questionnaire translation methods. In short, the consensus was that there is no consensus regarding best practices; Most researchers opt to use mixed-methods approaches to limit costs.
I then chose a few translation methods that researchers have taken or proposed and broke them down using hierarchical task analysis. The diagrams here represent two of the four breakdowns. Common features were the use of independent translators, using a forward-backward translation methodology and iteration.
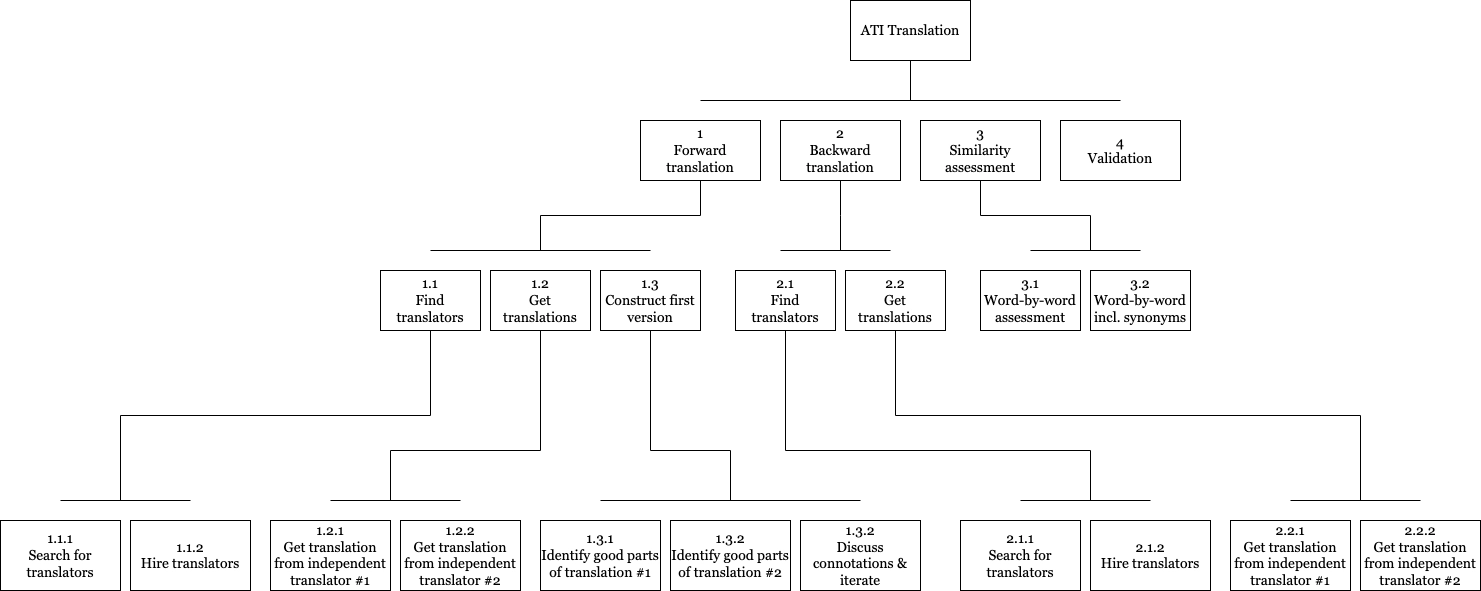
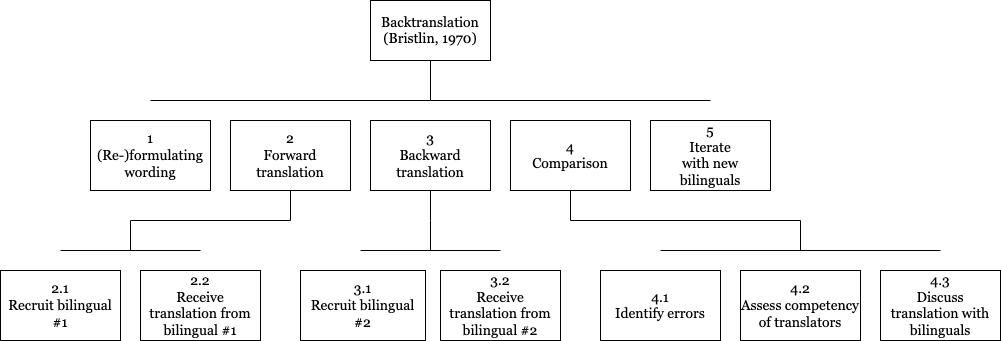
Another insight gained from the literature review was that in questionnaire translation, the direct correctness of the translated questionnaire is not as much a concern as capturing the semantics subtleties of the original version. Therefore, a LLM-powered questionnaire translation tool might benefit from delivering feedback regarding the semantic similarity of the translated version and the original.
Wireframing
After some initial pen-and-paper sketching and looking to online translation tools for inspiration, I constructed a semi-interactive prototype in Figma that could be used to communicate the idea to and test with two participants, both of whom had worked in HCI research before.
The interactive Figma prototype had a few notable issues that were uncovered by running basic usability tests.
In the first view, separating the entry of original items in their own text fields decreased their perceived editability. Moreover, participants would have preferred a single text are for copying and pasting items in bulk. The “add” button for adding new items was also visually too similar (size, shape, positioning) to the text fields.
In the second view, intended for editing and backtranslating the items, the buttons in the middle created too much visual separation between the original and the translated items. It did not help that the buttons were difficult to understand without tooltips. The most significant issue with this view, however, was that the flow of the system was illogical: in the first view, items were added in the center of the screen, then the translated items would appear on the right-hand side, and to compare the translations to the original the user would have to move their gaze from right to left.
In the screen that displayed the “results” of the evaluation, the identification of the measures was an issue. Both testers would also have liked to have more information regarding the two measures. Another issue with having the evaluations in a separate view / pop-over was that especially non-native translators would have to rely too much on recalling the feedback when going back to edit the translations.
Prototype Development
After initial tests, DeepL was selected to be the translation provider as its translation system results in more consistent translations and avoids the LLM-related issue of hallucination. GPT-4 was used to generate the numeric and verbal translation quality evaluations.
Based on the literature review, two translation quality evaluations were included. The first one, GEMBA, presented by Kocmi & Federmann in 2023, simply prompted a single numeric value between 0 and 100 that represented the quality of the translation.
The second evaluation metric was custom-made and prompted GPT to evaluate the semantic similarity of the original and the translation, and to return a numeric score for the similarity, justifications for the score, as well as suggestions for improving the score in JSON.
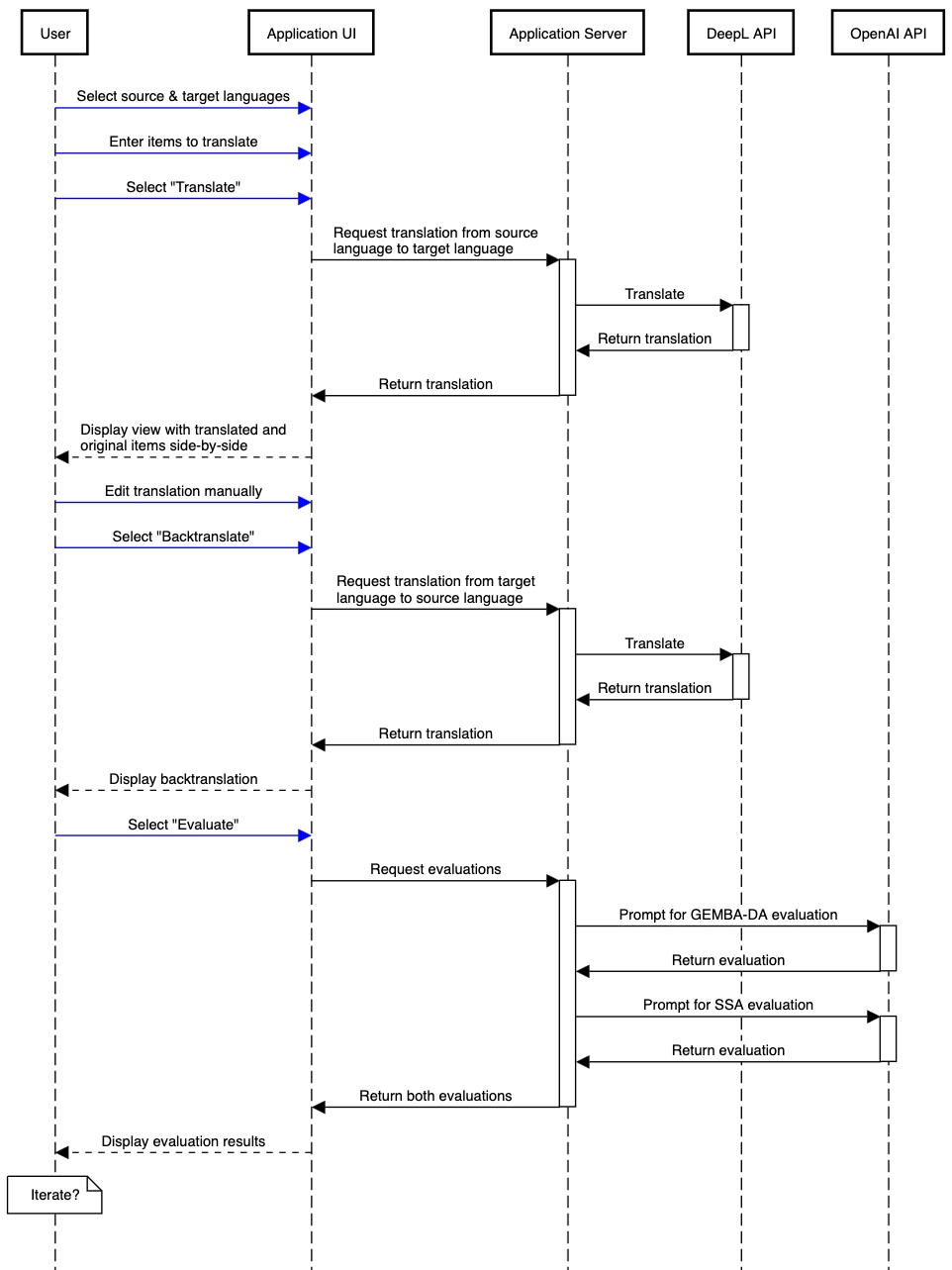
The prototype was built to be a web application so that it could easily be tested with participants recruited online. The application’s frontend was built with React and styled primarily with components from the ChakraUI library. The server was developed in Python with Flask and handled translating items with DeepL and requesting evaluations from ChatGPT. The application architecture and the process of translating a questionnaire is pictured in the sequence diagram below.
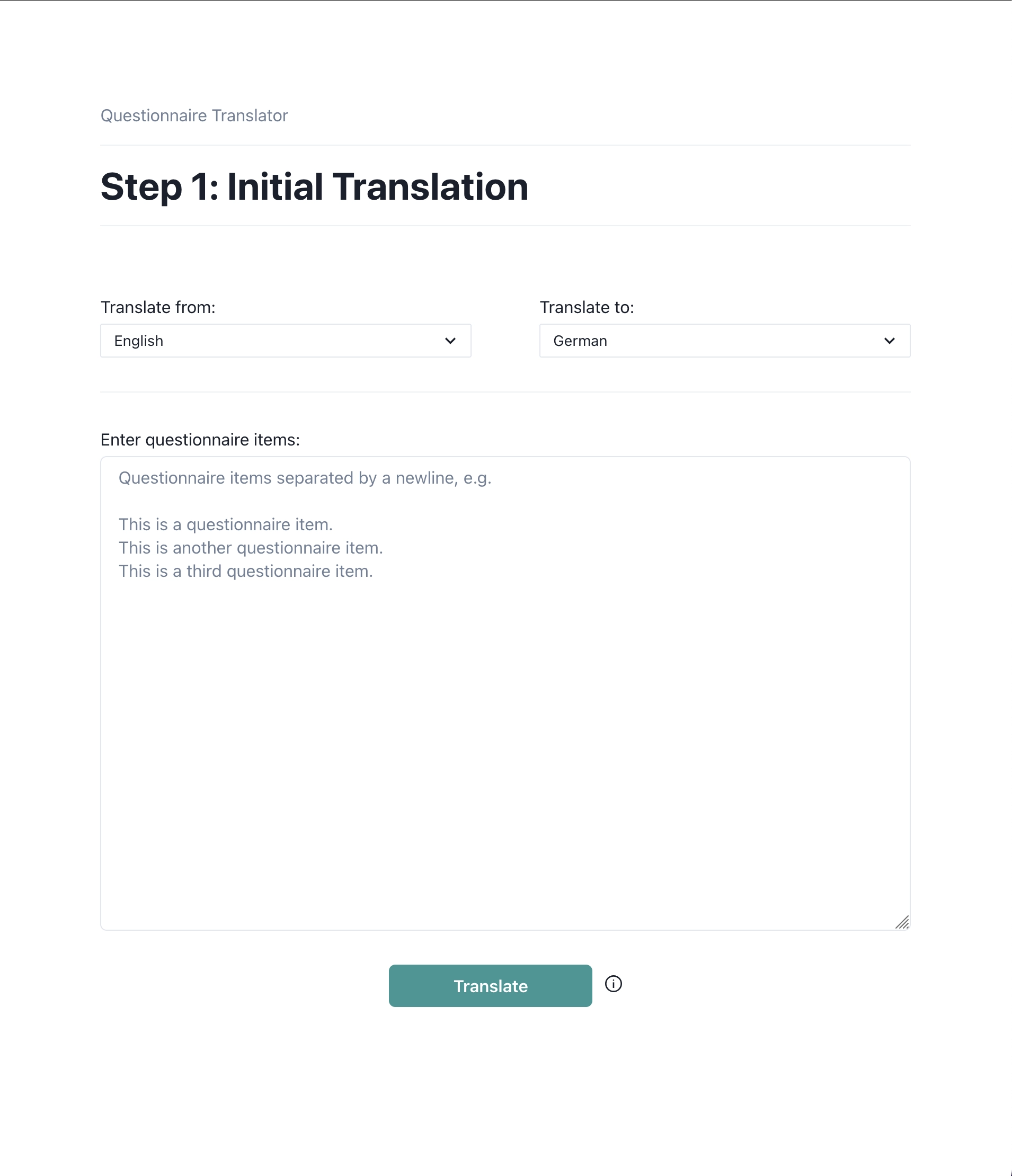
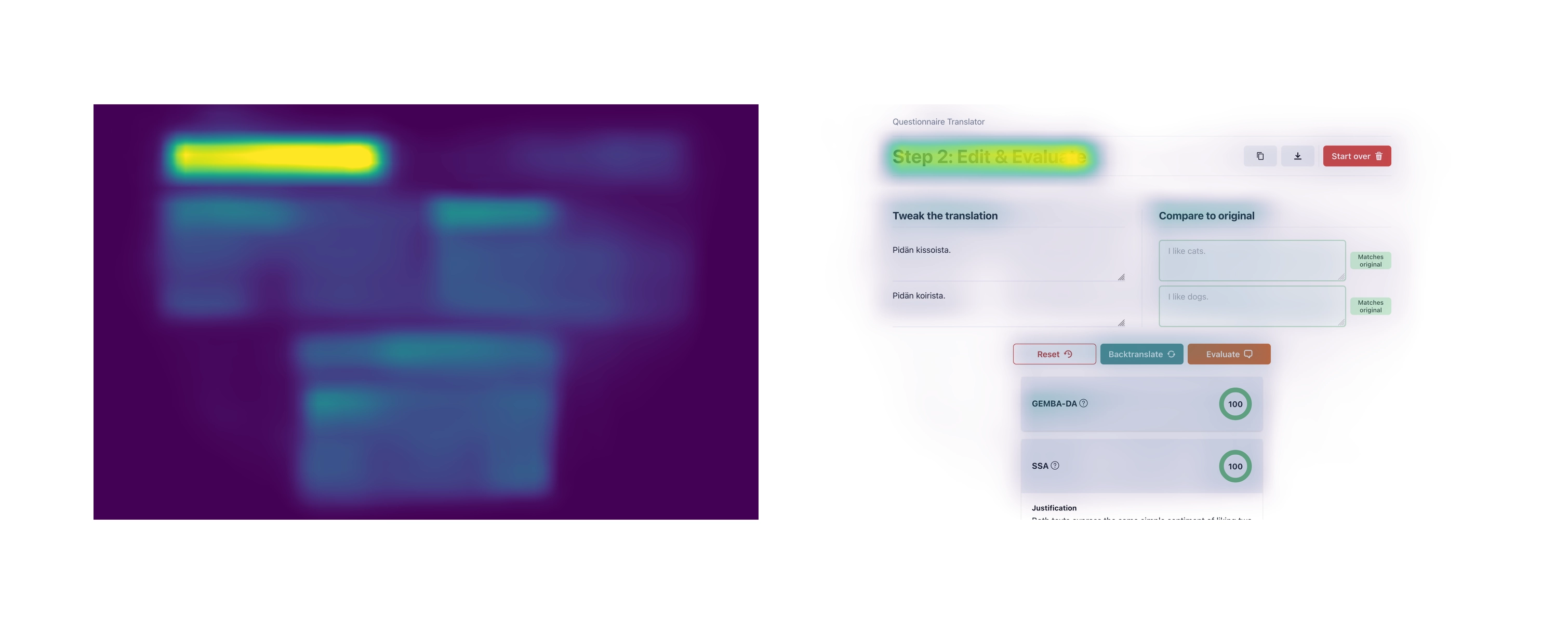
The final version of the prototype consists of two views. In the first one, users can select the original language of the questionnaire to be translated as well as the language that they wish to translate to. Then, they can manually enter or copy-paste the items to be translated to a text area. Hovering over the info icon next to the “translate” button reveals a tooltip noting that translations are performed with DeepL.
The second view incorporates the backtranslation and evaluation functionalities. Users can edit the translated items to their liking, and pressing the “backtranslate” button translates them back to the original language for comparison against the original version. The “evaluate” button prompts ChatGPT for the two evaluations, which are then displayed in the same view, below the comparisons. Additional features include the ability to reset the translation side to its initial state, as well as either copying or downloading the translated items.

As a final measure, I tested the interface’s visual hierarchy by using the UMSI functionality of the Aalto Interface Metrics online tool.
Results
(N.B. The full study is described in the preprint.)
Finally, I conducted two online studies (n=10; n=20) in which participants recruited via Prolific translated two separate questionnaires (affinity for technology scale, ATI; 10-item big five inventory, BFI-10) from English to an another language (S1, German; S2, Portuguese). In both studies participants managed to, using the tool, achieve similar evaluation ratings to versions of the questionnaires translated using traditional methods. Moreover, participants found the experience of using the tool enjoyable and had a high level of satisfaction with the suggestions provided by the semantic similarity analysis.
In conclusion, the prototype tool developed showed promise in LLM utilization for translating questionnaires. While the tool does not eliminate the need for running validation studies, LLM assessments of translation quality could help researchers with less resources practice high-quality questionnaire-based research in languages other than English.